«Наука в Сибири»
№ 35-36 (2670-2671)
11 сентября 2008 г.
ИНСТИТУТЫ СО РАН
ОБЪЕДИНЯЮТ ВЫЧИСЛИТЕЛЬНЫЕ РЕСУРСЫ
Н.А. Колчанов, директор ИЦиГ СО РАН, академик
Б.Г. Михайленко, директор ИВМиМГ СО РАН, академик
Основными направлениями деятельности Сибирского суперкомпьютерного центра (ССКЦ) при институте ИВМиМГ СО РАН являются: обеспечение вычислительными ресурсами институтов СО РАН и университетов Сибири по проведению математического моделирования в фундаментальных и прикладных исследованиях; координация работ по развитию суперкомпьютерных центров Сибири, осуществляемая Советом по супервычислениям при Президиуме СО РАН; организация обучения специалистов СО РАН и студентов университетов (НГУ, НГТУ, СибГУТИ) методам параллельных вычислений на суперкомпьютерах (поддержка ежегодных зимних и летних школ по параллельному программированию для студентов); сотрудничество с Intel, HP и промышленными организациями, тестирование новых процессоров и серверов на задачах пользователей; сетевое взаимодействие с другими суперкомпьютерными центрами СО РАН, Москвы и других городов России, а также зарубежных стран, совместная разработка технологий распределенных вычислений.
В июне 2008 года на базе ССКЦ открыт Центр компетенции СО РАН-INTEL, основными задачами которого являются: внедрение современных вычислительных технологий на базе разработок фирмы Intel и достижений СО РАН в промышленное производство Сибирского региона; обучение современным вычислительным технологиям на базе разработок фирмы Intel организаций добывающих отраслей, промышленности, науки и ВУЗов; оказание консультаций по параллельному программированию и вычислительных услуг на базе кластеров, имеющихся в ССКЦ (платформы Intel Itanium2, многоядерным Quad-Core Intel® Xeon® 5300 в перспективе и др.) по параллельным супервычислениям; сравнительная оценка производительности новых разработок фирмы Intel в области технических и программных средств на реальных задачах, решаемых в ССКЦ.
Основу вычислительных мощностей ССКЦ в настоящее время составляют Новосибирский кластерный суперкомпьютер НКС-160, кластер МВС-1000М производства ФГУП «НИИ Квант» и сервер hp Integrity rx4640-8.
Кластер НКС-160, созданный на базе процессоров Intel Itanium2, является результатом сотрудничества с фирмами Intel и НР. НКС-160 состоит из 80 двухпроцессорных серверов hp Integrity rx1620 с объемом оперативной памяти 4 Гбайта на каждом сервере.
Архитектура кластера МВС-1000М состоит из 64-х двухпроцессорных серверов DEC Alpha 21264, по 2 Гбайта RAM на модуль.
 |
| Машинный зал Сибирского суперкомпьютерного центра. |
Общая производительность двух кластеров составляет около 1.5 терафлопс. В этом году Приборная комиссия СО РАН выделила ИВМиМГ финансирование на приобретение кластера производительностью порядка 3-х терафлопс.
Однако даже этих ресурсов явно недостаточно для решения многих актуальных научных и прикладных задач, стоящих перед институтами СО РАН. В частности, такого рода задачи стоят и перед биоинформатикой и системной биологией.
В пост-геномную эру объем данных в области молекулярной биологии и биомедицины непрерывно растет (Таблица 1).
 |
| Таблица 1. Молекулярно-биологические данные, их объемы и задачи биоинформатики, связанные с их обработкой. |
В настоящее время здесь сложилась ситуация, когда экспериментальные технологии в своем развитии значительно опережают биоинформатические средства их поддержки, анализа и интерпретации результатов экспериментов. Среди таких технологий скоростное секвенирование геномной ДНК; многолокусное генотипирование; многопараметрическое профилирование экспрессии генов с использованием ДНК-чипов, MPSS и других подходов; протеомные технологии, позволяющие анализировать протеомы органов, тканей и групп клеток с масс-спектрометрической расшифровкой аминокислотных последовательностей белков; методы биоинформатики, обеспечивающие автоматический конвейерный анализ и интерпретацию получаемых экспериментальных данных.
Широкомасштабное секвенирование геномов лишь усугубляет сложившуюся ситуацию, приводя к тому, что имеющуюся информацию принципиально невозможно осмыслить и переработать без использования специальных компьютерных средств, предоставляющих мощные вычислительные ресурсы.
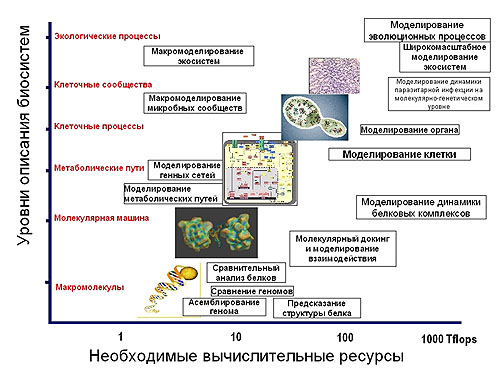 |
| Основные задачи биоинформатики, их сложность и ресурсоемкость. |
Основная задача интерпретации и анализа результатов первичной обработки молекулярно-генетических данных состоит в выяснении связи генов, белков и метаболитов с функционированием молекулярно-генетических систем, интеграции результатов с молекулярно-биологическими информационными ресурсами.
Знания о молекулярно-генетических взаимодействиях в клетке необходимы для решения широкого круга практически важных задач в области биотехнологии и агробиологии, биомедицины, фармакологии, в частности:
- поиск мишеней для создания лекарственных препаратов;
- оценка потенциальной эффективности и токсичности новых препаратов в доклинических испытаниях;
- идентификация биомаркерных молекул для создания эффективных диагностических систем;
- идентификация важных для продуктивности сельскохозяйственных культур генов;
- выбор генов-кандидатов для генотипирования.
Эти задачи относятся к передовому краю науки и их решение позволяет получать принципиально новые прорывные результаты в биологии и близких к ней областях. Однако для их решения требуются большие затраты вычислительных ресурсов.
В частности, для решения задачи предсказания белок-белковых взаимодействий в масштабах протеома целого организма (интерактома) требуется проверка всех парных взаимодействий белков этого организма. Среднее время, требуемое программе для определения взаимодействий пары белков с учетом использования набора из нескольких методов, составляет от 10 минут до нескольких часов. Следует отметить, что если число известных белков в E.coli составляет ~ 1870, то у высших организмов оно оценивается в 10-30 тысяч, что существенно увеличивает время счета и требует высокопроизводительных вычислений.
В Сибирском отделении РАН для решения задач современной биологии создается Сибирский центр геномных, протеомных и биоинформационных технологий. Он будет оснащен современным высокопроизводительным оборудованием для секвенирования геномов бактерий и эукариот; изучения протеом (т.е. всех белков) микроорганизмов, растений, животных и человека; а также для высокопроизводительных вычислений в области биоинформатики. Создание нового центра коллективного пользования ведется в рамках программы Сибирского отделения РАН «Геномика, протеомика, биоинформатика» на базе ряда институтов СО РАН: Международного томографического центра, Института химической биологии и фундаментальной медицины, Института цитологии и генетики, Института биофизики и Лимнологического института. Эта программа впервые в России открывает возможность осуществления полного цикла исследований бактериальных и эукариотических геномов: от их секвенирования до компьютерной аннотации и предсказания пространственных структур белков и реконструкции генных сетей.
Одна из задач центра — реализация проекта «Описторхоз». Геном O. felineus состоит из примерно
Оценка компьютерных мощностей, требуемых для выполнения проектов в рамках программы Сибирского отделения РАН «Геномика, протеомика, биоинформатика» показала, что для решения биоинформатических задач существующих вычислительных ресурсов Сибирского Отделения будет явно недостаточно.
Поэтому в рамках этой программы выделяется финансирование на создание специализированного вычислительного комплекса, ориентированного на решение задач биоинформатики и системной биологии, который будет включать: высокопроизводительный вычислительный кластер, параллельную кластерную систему хранения данных, файловый сервер с долговременным хранилищем данных, систему резервного копирования, сервера баз данных, графические станции для молекулярного дизайна. Этот вычислительный комплекс будет установлен в ССКЦ и интегрирован с вычислительными ресурсами СО РАН и НГУ.
Такого уровня вычислительные ресурсы в настоящее время уже не являются необычными. В частности, в МГУ установлен вычислительный кластер с пиковой производительностью 60 Тфлопс и планируется расширение до 100 Тфлопс; в ТГУ — кластер с производительностью 12 Тфлопс; в СФУ — кластер с производительностью 19 Тфлопс.
Для организации работы с этими вычислительными ресурсами в области биоинформатики в результате соглашения между ИЦиГ СО РАН и ИВМиМГ СО РАН был создан межинститутский сектор по высокопроизводительным вычислениям в биоинформатике. Основной целью этого сектора является создание интегрированной информационно-программной среды для поддержки исследований на базе высокопроизводительного экспериментального оборудования: (а) обработки первичных данных, получаемых с использованием экспериментальных технологий геномики, протеомики, масс-спектрометрии, микроскопии и др.; (б) обеспечения доступа к распределенным мировым информационным ресурсам в области геномики, транскриптомики, протеомики, клеточной биологии; (в) поддержки компьютерного анализа экспериментальных данных высокопроизводительными вычислительными ресурсами; (г) моделирования молекулярно-генетических систем и процессов, экспериментально изучаемых с использованием методов геномики и протеомики.
Успех в решении запланированных задач будет базироваться на большом опыте, полученном при решении аналогичных задач в СО РАН: компьютерной сравнительной геномике, протеомике, реконструкции, анализе и моделировании генных сетей, компьютерному конструированию потенциальных лекарственных препаратов.
В частности, проведены исследования генетических механизмов эволюционной адаптации археобактерий к жизни в условиях высокого давления. Эта работа выполняется в рамках интеграционного проекта СО РАН 49 совместно с НИЧ НГУ (акад. В. В. Болдырев). В результате проведенной работы было выявлено 110 генов, в которых на этапе дивергенции группы барофильных археобактерий рода Pyrococcus фиксировались адаптивные замены. Функции этих генов относятся преимущественно к работе мембран, метаболизму аминокислот и синтезу белков. По-видимому, именно эти процессы функционирования микроорганизмов претерпевают наиболее сильную модификацию в ходе приспособления к жизни при повышенных давлениях.
Решалась задача широкомасштабного анализа научных публикаций и автоматического извлечения знаний о молекулярно-генетических взаимодействиях и их ассоциациях с заболеваниями с использованием компьютерных методов text-mining, разработанных в ИЦиГ СО РАН.
В ИЦиГ СО РАН решались задачи поиска молекулярных мишеней для действия лекарственных препаратов, в частности, против вируса гепатита С. Использовались методы молекулярного докинга, методы молекулярного моделирования (молекулярная механика, молекулярная динамика), методы скрининга библиотек химических соединений, методы количественного анализа взаимосвязи структура-активность (QSAR) и так далее.
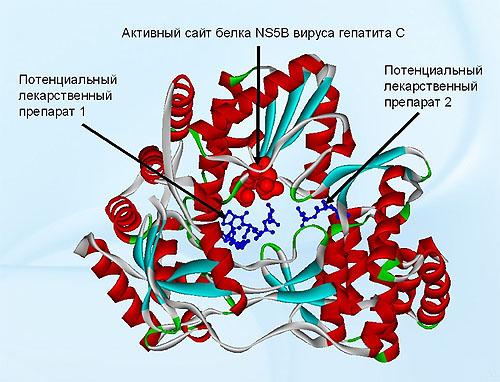 |
| Теоретическая модель взаимодействия белка NS5B вируса гепатита С с потенциальными лекарствами, рассчитанная с помощью компьютерной системы PDBSite и PDBSiteScan. |
В ФГУН ГНЦ ВБ «ВЕКТОР» проводилось изучение модели химерных белков с применением средств ССКЦ. Для предотвращения дальнейшего распространения ВИЧ необходимо создание эффективной профилактической вакцины, задача разработки которой является крайне актуальной на сегодняшний момент.
Построены модели химерных белков, несущих консервативный участок (MPER район) вирусного белка gp41. На базе таких белковых конструкций могут быть созданы вакцины против ВИЧ. Проведено моделирование пространственной структуры белковой конструкции по гомологии с использованием программы Modeller. Для релаксации и получения динамических характеристик моделей использовался свободно распространяемый пакет молекулярной динамики GROMACS. Проведен анализ различных вариантов встроек MPER района в белки-носители. Планируется синтез выбранных химерных белков и экспериментальная проверка их антигенных свойств.
В рамках программы фундаментальных исследований Президиума РАН «ПРОИСХОЖДЕНИЕ И ЭВОЛЮЦИЯ ЖИЗНИ НА ЗЕМЛЕ: ФИЗИКО-ХИМИЧЕСКИЕ, ГЕОЛОГИЧЕСКИЕ, ПАЛЕОНТОЛОГИЧЕСКИЕ И БИОЛОГИЧЕСКИЕ ПРОБЛЕМЫ» группа исследователей, работающая в ИК СО РАН и ИВМиМГ СО РАН, изучает образование планет как самоорганизацию материи, как результат воздействия протозвезды на свое окружение с учетом обратных связей и химических реакций в среде. Для ответа на поставленные вопросы на параллельных супер-ЭВМ проводятся вычислительные эксперименты для решения фундаментальных уравнений гравитационной физики и газовой динамики в трехмерных декартовых и цилиндрических координатах с учетом многокомпонентности среды, реалистичного уравнения состояния газа, корректного учета границы газ-вакуум. Разработаны численные алгоритмы трехмерного моделирования пылевой компоненты в декартовых и цилиндрических координатах. Разработана численная модель для трехмерного моделирования нестационарных процессов в гравитирующих системах с самосогласованным полем с модулем для расчетов химических реакций. В модель, основанную на решении уравнения Пуассона для гравитационного поля, уравнения Власова для крупных тел и газодинамических уравнений, включено вычисление температуры. Расчеты проводились на МВС-1000М Сибирского суперкомпьютерного центра. Исследованы солитоноподобные структуры в двухфазной среде, состоящей из пылевой и газовой компонент, при наличии центрального тела. Получены численные данные о джетах — струях вещества в галактических дисках.
 |
| Плотность пылевой компоненты протопланетного диска. |
Важнейшим направлением нашей деятельности является подготовка молодых специалистов в области высокопроизводительных вычислений в биоинформатике, которая ведется в Новосибирском государственном университете на ФЕН (кафедра информационной биологии — http://www.bionet.nsc.ru/chair/cib/), факультете информационных технологий, механико-математическом и физическом факультетах.
Каждые два года ИЦиГ СО РАН организует школы молодых ученых по высокопроизводительным вычислениям в биоинформатике и международные научные конференции по данному направлению (http://www.bionet.nsc.ru/).
Мировой опыт показывает, что современная биология и медицина немыслимы без использования высокопроизводительных ресурсов. Развитие этих ресурсов в СО РАН позволит нашим институтам выходить на решение прорывных научных задач.
стр. 4-5