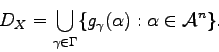Прежде всего, следует заметить, что понятие ресурса носит слишком общий характер и поэтому основным объектом манипуляции информационных систем является частный случай ресурса -- документ. На данном этапе определим документ ![]() как ресурс, обладающий структурой и являющийся отражением некоторой информации о реальном мире.
как ресурс, обладающий структурой и являющийся отражением некоторой информации о реальном мире.
Электронные документы должны иметь ряд преимуществ по сравнению с документами другой природы, поскольку, как правило, обладают автоматизированными средствами каталогизации, поиска и изменения. Более того, процедура получения твердой копии электронного документа заметно проще, чем обратная процедура.
Можно сказать, что здесь документы информационной системы рассматриваются как объекты независимого происхождения, существующие независимо друг от друга. Наиболее наглядный пример -- это первые веб-сайты, представляющие собой набор HTML-страниц, каждая из которых хранилась в виде отдельного статичного файла. Недостатки такой организации быстро стали очевидными -- при достаточно большом количестве документов сайт становится плохо управляемым и не способен быть постоянным источником актуальной информации, поскольку требует больших человеческих ресурсов для обновления. Поэтому сайты с хранилищем документов на основе файлов могут использоваться только для создания систем с маленьким числом документов, содержащих редко обновляемую информацию.
Как уже было отмечено, управление большим количеством документов по отдельности представляется крайне неэффективным. Поэтому необходимо выделить подкласс информационных систем, в которых операции можно будет осуществлять с целыми группами документов. Один из наиболее хорошо зарекомендовавших себя подходов к созданию ИС основывается на понятии коллекции.
Коллекцией называется множество документов, имеющих одинаковую структуру и описывающих одну и ту же сущность.
Прежде чем перейти к более строгому определению коллекции, следует пояснить, что такое структура документа. Один из главных признаков информационной системы (или электронной библиотеки) -- существование средств ведения каталогов документов, которые позволяют реализовать функции ``эффективного'' поиска и классификации документов. Для организации каталога документов ИС используется понятие метаинформации или метаданных документа.
Ранее документ был определен, как ресурс, содержащий информацию и обладающий структурой. Структура документа задается набором элементов, между которыми могут быть определены отношения. Структура документа в ИС должна описываться его метаданными.
Метаданные документа могут быть указаны различными способами. Один из них известен еще со времен языка разметки текстов SGML![[*]](footnote.png) , где для каждого SGML-документа существовало его DTD-определение, которое строго специфицировало структуру разметки. Позже концепция DTD легла в основу XML-схем -- нового средства описания структуры разметки, снабженного больший функциональностью, чем его предок. Как и DTD-описание, XML-схема определяла элементы структуры документа и отношения между ними. Добавление возможностей описания качественно новых типов отношений привело к созданию технологии RDFS, а еще позже -- языка онтологических описаний OWL.
, где для каждого SGML-документа существовало его DTD-определение, которое строго специфицировало структуру разметки. Позже концепция DTD легла в основу XML-схем -- нового средства описания структуры разметки, снабженного больший функциональностью, чем его предок. Как и DTD-описание, XML-схема определяла элементы структуры документа и отношения между ними. Добавление возможностей описания качественно новых типов отношений привело к созданию технологии RDFS, а еще позже -- языка онтологических описаний OWL.
Определение метаданных документа, согласно рекомендациям OSI, должно
осуществляться посредством использования схем данных. Схемы данных являются спецификациями элементов структуры
документа и их семантического значения. Например, схема Dublin Core декларирует метаданные для составления самых общих описаний электронных документов. Отметим, что рекомендации группы DCMI предлагают, чтобы все другие
существующие и создаваемые схемы данных включали в себя обязательный набор элементов Dublin Core для унификации доступа к ним.
Перейдем к описанию формальной модели ИС и дадим несколько определений.
Определение. Скриптом назовем функцию
![]() , где
, где ![]() -- некоторая
параметризация множества документов данной коллекции. Каждому элементу
-- некоторая
параметризация множества документов данной коллекции. Каждому элементу ![]() скрипт сопоставляет документ
скрипт сопоставляет документ
![]() , структура которого идентична структуре других документов этой коллекции, а содержание документа определяется параметром
, структура которого идентична структуре других документов этой коллекции, а содержание документа определяется параметром ![]() .
.
Каждый документ информационной системы задается парой (структура, наполнение), где структура задается с помощью функции-скрипта, а наполнение определяется аргументом, передающимся этой функции.
Обозначим множество всех документов ИС:
Прежде всего, заметим, что обозначение ![]() в известной степени условно. В данном случае не предполагается, что все параметры однородны и их значения принадлежат одному и тому же множеству
в известной степени условно. В данном случае не предполагается, что все параметры однородны и их значения принадлежат одному и тому же множеству ![]() , поскольку они могут иметь булевские, числовые, строковые и другие типы. Здесь
, поскольку они могут иметь булевские, числовые, строковые и другие типы. Здесь ![]() являет собой, своего рода, собирательный образ множеств значений различных
типов, а
являет собой, своего рода, собирательный образ множеств значений различных
типов, а ![]() -- декартово произведение любой их конечной комбинации. Также явно не указывается, но в дальнейшем
предполагается, что все коллекции имеют свои собственные наборы параметров
-- декартово произведение любой их конечной комбинации. Также явно не указывается, но в дальнейшем
предполагается, что все коллекции имеют свои собственные наборы параметров ![]() , не зависящие друг от друга.
, не зависящие друг от друга.
Теперь мы можем определить коллекционную информационную систему ![]() как информационную систему, состоящую из коллекций документов:
как информационную систему, состоящую из коллекций документов: